Anubus - When search engines go too far
Why stop being in search engines?
Last year, I noticed thatmy git server was starting to slow down, and use a lit more memory. Not only that, but web traffic from it was never ending. This isn't normal for that type of server, especially when I'm the most active user by far, and I hardly touch it. I went to see what was happening, and it turned out to be web crawlers. Nothing but bots loading every page, just so places like google and duckduckgo searches can find the page. Problem is that on a git server, files are generated on the fly, and large projects like QMK, which I used to keep a personal copy of, could generate literally billions of pages. Not only is it liking at every file, but every version of every file that's ever existed.
In comes Anubus
Anubus is basically a safe guard. When a new visitor shows up to a page behind it, it asks your to do work. Not you the user, but your computer. Once you do this work, you move on, and it remembers that you are a person, and stays out of the way. When you are a bot however, it asks you to do increasingly more work, until you give up because it's no longer worth it.
Does it really work?
In my experience, yes! I've protected two of my sites with it, and noticed instant results. It doesn't take an expert to see what moment that I implemented Anubus into my services.
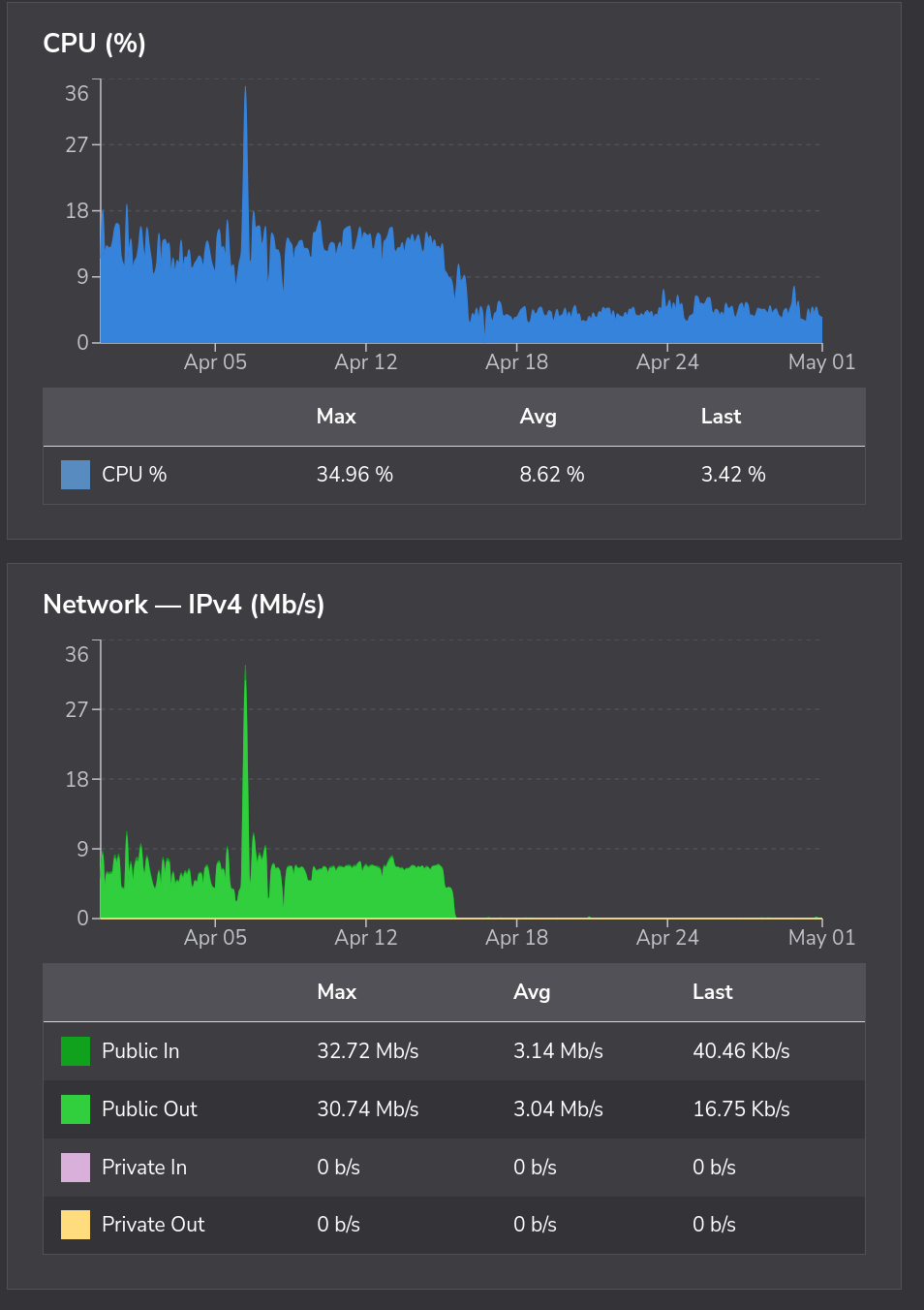
Both https://search.kdb424.xyx and https://git.kdb424.xyz are behind an Anubus proxy, and I've had a great experience. The only rare gripe I have with it on the searxng instance is when it has to verify you are human, it can "eat" your search. This is probably something that I can fix, but it's a very minor gripe in the mean time.
How do I use this?
I'd recommend checking out the Anubus project page to see how it fits into your workflow. I've put all of my docker configs up on my git, and I'll be making a post about that later. Hopefully this has been of some help though!